Tag 10 – Linked Data 1/1 (BIBFRAME & RiC)
One last Tango
01 Ein neuer Begriff zum Abschluss der Discovery Systeme: Central Index
Kurz vor dem Abschluss habe ich noch einen neuen Begriff gelernt: Central Index. Der Index harvestet Daten (Metadaten, Abstracts, Schlagwörter, Volltexte) von Verlagen, Datenbanken und Open-Access-Sammlungen und kann von Bibliotheken in das eigene Discovery System eingebunden werden - parallel zu den Daten, die aus dem lokaeln Bibliothekskatalog kommen.
Ein Beispiel aus der Praxis: Die Hochschulbibliothek der ZHAW beschreibt in ihrer Rechercheanleitung folgende „Suchräume“:
- Suchraum Bücher, Zeitschriften, Bilder = Suche im Bibliotheks-Katalog (eigene Daten)
- Physischer Bestand der Bibliotheken, Bücher, Zeitschriften, CDs, DVDs, Karten, Medienpakete etc.
- Teilweise elektronische Bestände der Bibliotheken (E-Books, E-Journals)
- Suchraum Artikel und mehr = Primo Central Index (von Anbieter Ex Librix)
- Suche in einem noch umfangreicheren Informationsangebot von Verlagen, Datenbanken und Aggregatoren
- Suche in Open-Access-Zeitschriften und -Repositorien
- Zusätzliche integrierte Dokumenttypen wie E-Book-Kapitel, Konferenzberichte, Reviews etc.
02 Linked (Open) Data
Linked Open Data (LOD) nutzt das Internet, um frei verfügbare Daten, die eine Beziehung haben, miteinander zu verbinden und ihnen einen Kontext zu geben. Die Daten sind über einen URI (Uniform Resource Identifier) klar identifiziert und können so geteilt und verlinkt werden. Die miteinander verknüpften Daten ergeben ein weltweites maschinenlesbares Netz (Semantic Web).
Zur Codierung und Verlinkung der Daten werden folgende Standards bzw. Werkzeuge gebraucht:
- RDF (Resource Description Framework): Standard von W3C. Macht Aussagen über beliebige „Dinge“ (Ressourcen). Aussage besteht immer aus einem Tripel (Subjekt, Prädikat und Objekt).
- OWL (Web Ontology Language): baut auf RDF auf. Beschreibungssprache für Ontologien (logische Beziehungen von Begriffen)
- SPARQL (spa RDF Query Language): graphenbasierte Abfragesprache für RDF (z.B. analog SQL für relationale Datenbanken)
Diese Themen beschäftigen uns auch gerade im Modul SESY (Semantische Systeme für Informationsverarbeitung). Die Begriffe RDF und Ontology hatten wir zwar schon mal gehört in den Grundlagenmodulen - aber erst jetzt, wo die Theorie mit der PRaxis verbunden wird, macht alles irgendwie Sinn. Vorher waren diese Konzepte und Standards sehr abstrakt für mich.
03 Aktuelle Datenmodelle für Metadaten, die auf Linked Data basieren
BIBFRAME
Von diesem Datenmodell haben wir ja schon ein paar Mal gehört, als Nachfolger von MARC21, Details dazu folgen aber erst jetzt - und auch nur theoretisch:
- basiert auf den Regelwerken RDA (Resource Description and Access) und FRBR (Functional Requirements for Bibliographic Records), aber nicht vollständig und starr
- besteht aus BIBFRAME Model und BIBFRAME Vocabulary:
- BIBFRAME Model
- unterscheidet zwischen Work, Instance und Item
- definiert die Entitäten Agent (Personen&Körperschaften der Entstehung des Werks), Subject (Themen&Personen) und Event (Inhalt des Werks)
- BIBFRAME Vocabulary
- definiert Konzepte und deren Eigenschaften zur Beschreibung der Entitäten
- Ontologie umfasst Klassen (Class), die über spezifische Eigenschaften (Property) verfügen (basierend auf RDF/OWL?!)
- BIBFRAME Model
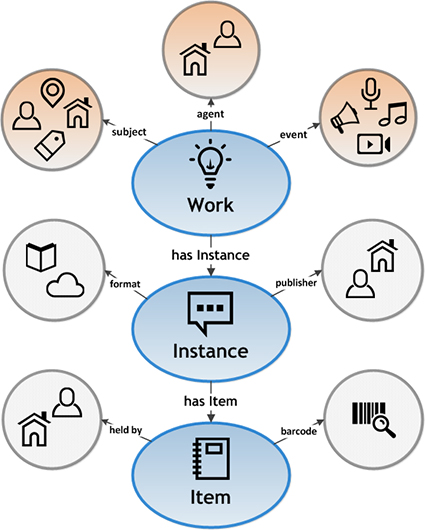 Quelle: https://www.loc.gov/bibframe/docs/bibframe2-model.html
Quelle: https://www.loc.gov/bibframe/docs/bibframe2-model.html
Was unterscheidet denn nun MARC21 und BIBFRAME?
Hier wird vorallem auf das Linked Data Prinzip hingewiesen: „Instead of bundling everything neatly as a “record” and potentially duplicating information across multiple records, the BIBFRAME Model relies heavily on relationships between resources (Work-to-Work relationships; Work-to-Instance relationships; Work-to-Agent relationships). It manages this by using controlled identifiers for things (people, places, languages, etc).“ Quelle: https://www.loc.gov/bibframe/faqs/#q04
Records in Context (RiC)
Auch von diesem Datenmodell haben wir schon mal gehört, bei den Standards und Systemen aus dem Archiv:
- erster Entwurf wurde 2016 vorgestellt
- Ziel dieses neuen Standards ist die Zusammenführung der vier bestehenden (archivarischen) Standards:
- ISAD(G): Internationale Grundsätze für die archivische Verzeichnung
- ISAAR(CPF): Internationaler Standard für archivische Normdaten (Körperschaften, Personen, Familien),
- ISDF: Internationaler Standard zur Beschreibung von Funktionen,
- ISDIAH: Internationaler Standard für die Verzeichnung von Institutionen mit Archivbeständen.
- aber nicht nur Harmonisierung der 4 Standards, sondern auch Anpassung der veralteten archivischen Verzeichnungspraxis an die heutigen digitalen Möglichkeiten
- an die Stelle einer geschlossenen, strikt hierarchisch organisierten Tektonik tritt ein offenes Netz möglicher Beziehungen (= Linked Data) und dies soll neue und mehrfache Beziehungen zwischen Entitäten ermöglichen
(Schleichwerbung FHGR: In der Schweiz gibt es die Projektgruppe ENSEMEN, die an einer schweizerischen Ausprägung des neuen Standards RiC arbeitet (mit Beteiligung von Niklaus Stettler der FH GR))